연결리스트
메모리 상에서는 데이터가 비연속적으로 저장되어 있는 선형 자료구조
물리적으로 연속되어 있지 않고 논리적으로 다음 노드의 주소값을 저장해서 논리적으로 연속성을 구현
[데이터, 다음/이전 노드 주소값] 쌍으로 저장
head, tail 노드의 주소값을 항상 저장하고 있어 양 끝에서는 빠르게 접근 가능

연산
삽입
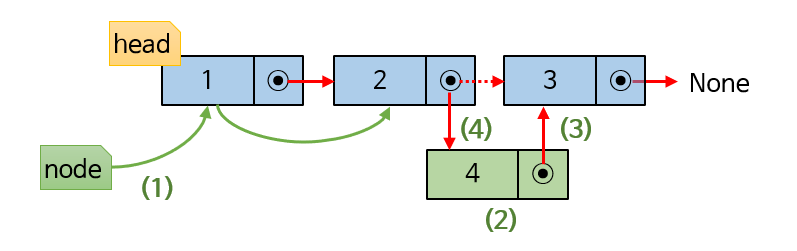
1. 삽입하고 싶은 직전 노드까지 이동한다.
2. 새로운 노드를 생성해서 데이터를 넣는다.
3. 삽입하고 싶은 직전 노드에서 다음 노드의 주소값을 새로운 노드로 복사한다.
4. 삽입 직전 노드에서 다음 노드를 생성한 노드로 가리킨다.
삭제

1. 삭제하고 싶은 노드까지 이동한다.
2. 이전 노드의 다음 주소값을 삭제 다음 노드의 주솟값을 가리키게 한다.
3. 삭제 노드의 메모리 할당을 해제한다.
시간복잡도
| 어느 위치에서 데이터 삽입 | O(1) |
| x라는 데이터 탐색 | O(N) |
| i번째 데이터 변경 | O(N) |
사용사례
Java
Java에서는 연결리스트는 이전 다음 노드의 주소값이 저장되어 있는 Doubly LinkedList로 연결되어 있다.
리스트 복사
10만개의 같은 타입의 데이터를 저장하고 있는 연결리스트가 2개가 있다.
두개의 리스트를 하나로 합치고 싶다면, O(1)연산으로 리스트를 연결할 수 있다.
(tail -> head)를 연결하면 되기 때문이다.
두개의 배열을 하나로 합친다면 O(200000)연산이 수행된다.
'CS > Data Structure' 카테고리의 다른 글
| [Data Structure] 이진 탐색 트리(Binary Search Tree) (0) | 2025.07.30 |
|---|---|
| [Data Structure] 우선순위 큐(PriorityQueue), 힙(Heap) (0) | 2025.07.25 |
| [Data Structure] HashTable(해시테이블) (2) | 2025.07.25 |
| [Data Structure] 큐(Queue) (2) | 2025.07.22 |
| [Data Structure] 스택(Stack) (0) | 2025.07.21 |